
Understanding SegFormer: The Future of Semantic Segmentation

In the rapidly advancing field of Computer Vision, semantic segmentation serves as a foundational technique, employed in a variety of applications ranging from autonomous driving to precision agriculture.
Traditional models have long relied on convolutional neural networks (CNNs) to process images. But as the demand for flexibility and adaptability grows, the industry seeks a paradigm shift. Enter SegFormer—a semantic segmentation model that harnesses the prowess of transformers, renowned for processing non-grid structured data.
This article explores the nuances of SegFormer, examining its essential components and highlighting its distinct benefits.
Moreover, we'll guide you through training this powerful model on a custom vineyard dataset using the Ikomia STUDIO, a no-code platform.
Why consider Ikomia STUDIO?
Whether you're an expert in Computer Vision or just venturing into the field, this guide offers an in-depth look at SegFormer's transformative impact on semantic segmentation. Dive in and discover the next chapter of image segmentation.
SegFormer is a semantic segmentation model that embraces transformers’ potential to process non-grid structured data, such as images. Unlike traditional convolutional neural networks (CNNs) that process images in a grid structure, transformers can handle data with various structures, offering flexibility and adaptability in dealing with diverse data types and tasks.
SegFormer, introduced in the paper "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers" [2], has been designed to efficiently and effectively address the challenges of semantic segmentation.

SegFormer leverages a hybrid transformer backbone to extract features from input images. This involves a convolutional layer to process the input image, followed by a transformer to capture the global context of the image.
To handle objects and features of varying scales in an image, SegFormer amalgamates multi-scale feature maps derived from different transformer layers. This multi-scale feature integration enables the model to recognize and accurately segment objects of different sizes and shapes.
The Multi-Level Aggregation (MLA) head is a distinct component of SegFormer, which fuses feature maps from different levels, ensuring that the segmentation model can effectively utilize features from all scales. This is crucial for maintaining high-resolution details and recognizing small objects, enhancing the model's segmentation performance.
- Simplicity and efficiency: SegFormer introduces a simple yet effective architecture that doesn't require intricate designs or complex auxiliary training strategies, which are often used in conventional semantic segmentation models.
- Versatility: The model exhibits exceptional versatility, capable of handling a variety of segmentation tasks across numerous domains without requiring domain-specific adjustments or fine-tuning.
- Scalability: SegFormer demonstrates remarkable scalability, performing efficiently on images of different resolutions and scales.
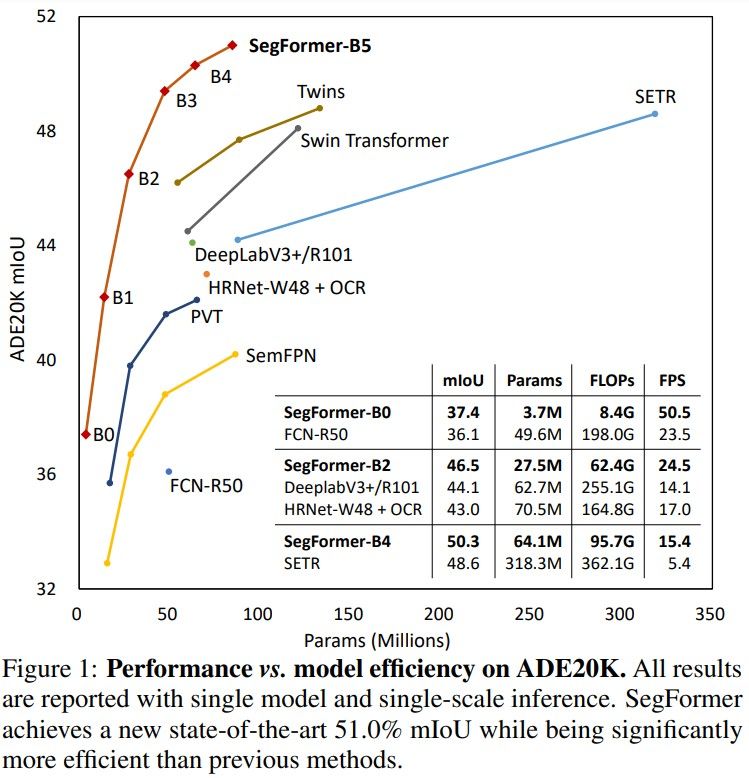
SegFormer has showcased exemplary performance across several benchmark datasets, such as ADE20K, Cityscapes, and Pascal Context, establishing new state-of-the-art results and underlining its efficacy and robustness in semantic segmentation.
This guide illustrates how to train SegFormer, a high-performing semantic segmentation model, on a custom dataset without engaging in any coding.
We aim to develop a model for a viticultural robot capable of autonomous driving in vineyards, enabling it to traverse and recognize obstacles within the inter-row spacing.
The development of an autonomous viticultural robot for vineyards could offer enhanced efficiency in farming by providing precision agriculture, labor savings, and sustainable practices. With capabilities like obstacle detection, data collection, and modular design, it promises to revolutionize vineyard management while reducing costs and environmental impact.
For this tutorial, we're utilizing a concise vineyard dataset [1] from Roboflow with 71 images to illustrate the training of our custom segmentation model. While this compact dataset is ideal for demonstration purposes, a production-level application would demand a larger, more varied dataset to guarantee model accuracy and resilience. The dataset contains four labels: Plant, trunk, sky, and soil.

Training a custom object detector has never been easier. The Ikomia HUB provides all the necessary building blocks for our training pipeline, and it's ready to use with no code required. You'll be able to start your training in just a few steps.
To get started, you need to install the STUDIO desktop app for Computer Vision available for both Windows and Linux users.
STUDIO offers a no-code interface, making computer vision tasks accessible without compromising on depth or performance. While it's lightweight on system resources, users still maintain detailed control over hyper-parameters. Professionals and beginners alike can navigate its features with ease.
Plus, its open-source foundation ensures transparency, allowing users to inspect, modify, and adapt the tool to their evolving needs.
To build a custom training workflow, we only need two algorithms.

The initial step involves converting the dataset into the Ikomia format to ensure compatibility with all training algorithms.
The annotations within the infected leaves dataset are stored utilizing the Common Objects in Context (COCO) format. This format allows for detailed annotations of objects within each image, using a .JSON file to maintain this information.
Subsequently, we efficiently train our semantic segmentation model, SegFormer, implemented from the Hugging Face framework.
This algorithm not only supports the SegFormer model but also includes various other model architectures, such as BeiT and Data2VecVision, offering flexibility to select the model that aligns best with your requirements.
For this tutorial, we've opted for the SegFormer-b2 model. The SegFormer-b2 balances both accuracy and computational demands, providing strong segmentation results without taxing system resources excessively. If you prioritize maximum accuracy and can accommodate higher computational needs, consider exploring the "b4" or "b5" variants.
1 - Navigate to the HUB within Ikomia Studio.
2- Search for and install sequentially the algorithms: dataset_coco and train_hf_semantic_seg.
The COCO dataset algorithm in STUDIO enables loading of any dataset in the COCO format and seamlessly integrates with your training algorithm. Additionally, once the dataset is loaded, STUDIO provides a visual inspection tool for your annotations, ensuring their accuracy and correctness.
1. Locate the algorithm:
2. Configure parameters:
3. Apply settings:
.gif)
With the dataset loaded, it's time to incorporate the SegFormer training job into the workflow.
1. Locating the algorithm:
Navigate to the process library (left pane) and search for the recently installed train_hf_semantic_seg algorithm.
2. Adjusting parameters before training:
Prior to initiating training, it's imperative to dive into and configure the available parameters to ensure optimal model training.

Click the 'Apply' button now to incorporate the infer_hf_semantic_seg algorithm into the current workflow; the training process will begin immediately.
With the smooth integration of MLflow, you can monitor the training progress in real-time. Parameters and metrics, including mean IoU, accuracy, and loss value, are automatically reported and can be viewed through the MLflow dashboard.
.gif)
Below are the results obtained from a run using a SegFormer b2 model trained for 10 epochs with an input size of 320 pixels:
At this stage, Ikomia STUDIO offers several options:

Once your custom model is trained, you can easily test it within Ikomia STUDIO. Close your previous training workflow and follow these steps:
a. Check ‘Model from checkpoint’
b. Browse to your custom model weight folder (user-folder/Ikomia/Plugins/Python/YoloTrain/data/models/train_hf_semantic_seg/outputs/nvidia/mit-b2/[timestamp]/checkpoint-120)
5. Press Apply

This article has delved into the mechanics and advantages of SegFormer, showcasing its simplicity, versatility, and scalability. Beyond just theory, we provided a hands-on guide on how to train this potent model on a custom vineyard dataset using the no-code Ikomia STUDIO platform.
Ikomia STUDIO's user-friendly and streamlined workflows make it an ideal platform for both novices and experts to explore and harness the latest advancements in Computer Vision. With no-code platforms like Ikomia, the future of semantic segmentation, and by extension, Computer Vision, is not only promising but also accessible to all.
With the Ikomia tools you can chain algorithms from different frameworks like TorchVision, YOLO, and OpenMMLab. This enables you to effortlessly construct more sophisticated and potent workflows. Explore the ID card information extraction solution we crafted, which leverages five state-of-the-art algorithms from diverse frameworks.
[1] STL Dataset from NeyestaniSetelCo
[2] doi.org/10.1609/aaai.v37i11.26477










.svg)


